פרק 22:
Java & XML
שימוש ב-XML
·
מהי XML
·
שימוש בJAXP- לביצוע parsing פשוט
מהי
XML
XML היא שפת סימון
בדומה
ל-HTML, גם XML
היא שפת סימון. XML איננה שפת תכנות שמאפשרת
פיתוח תכניות אשר מבצעות פעולות חישוב. בדומה ל-HTML גם
XML מורכבת, למעשה,
מתגיות אשר מסמנות מקטעי טקסט מן המסמך. בעוד שתפקידן של התגיות במסמכי HTML
הינו לומר לדפדפן כיצד להציג את מקטעי הטקסט שאותם הן מסמנות, במסמכי XML
תפקידן של התגיות הוא לומר מה המשמעות של אותם מקטעי טקסט. התגיות במסמכי XML
מוצמדות למקטעי הטקסט השונים ובכך הן מקטלגות אותם.
הקטע
הבא הוא דוגמא למקטע XML אפשרי:
<email>
<to> support@zindell.com </to> <from>haim_michael@yahoo.com</from> <subject>Java & XML</subject> <content> We love Java ! </content></email>
האפשרות
לכלול בתוך תגית XML תגיות XML
אחרות מאפשרת לעשות שימוש יעיל ב-XML כדי לייצג מידע
היררכי.
תגיות
ותכונות
בתוך
תגית XML ניתן לשלב תכונות (attributes) בדומה ל-HTML.
הדוגמא הבאה מציגה אפשרות זו:
<email to="support@zindell.com" from="haim_michael@zindell.com" subject="Java & XML">
<content> We love Java ! </content></email>
כפי
שדוגמא זו מציגה, ניתן לייצור מסמך XML בעל משמעות מסוימת
בשני אופנים: שימוש בתגיות בלבד או שילוב של תגיות ותכונות. בהמשך נדון בשיקולים
שאליהם יש להתייחס כאשר שוקלים את שתי האפשרויות.
אחד
ההבדלים בין מסמכי XML למסמכי HTML
הוא שבמסמכי XML מתקיימת רגישות
להבדלים בין אותיות גדולות לאותיות קטנות. הבדל נוסף הוא שמסמך XML
יכול לכלול מספר ריווחים רציפים (ב-HTML מספר ריווחים
רציפים הופכים לריווח יחיד).
כל
מסמך XML חייב להיחשב ל-
well-formedכדי שניתן יהיה לעבוד עמו. זהו הבדל גדול
ביחס ל-HTML. מסמך HTML
איננו חייב לעמוד בכל הכללים כדי שניתן יהיה להציגו. אחת הדרישות המרכזיות לכך
שמסמך ה-XML ייחשב ל- well-formed היא שלכל תגית התחלה תהיה גם תגית סיום
(ב-HTML ניתן היה לכתוב
תגית התחלה מבלי לסגור אותה בתגית סיום ועדיין להציג את המסמך בדפדפן). דרישה
מרכזית נוספת לכך שמסמך ה-XML יחשב ל- well-formed היא שכל צמד תגיות אשר
יכונן בתוך צמד תגיות אחר ישמור על מיקומם המתאים של התגיות. כך למשל, מסמך ה-XML
הבא איננו חוקי (איננו well-formed (:
<name>..<id>..</name>..</id>. כדי ששורה זו תהיה חוקית (תיחשב ל-well-formed) יש לרשום אותה כך:
<name>..<id>..</id>..</name>.
דרישה נוספת לכך שהמסמך ייחשב ל-well-formed
היא שהוא יכלול מרכיב אחד ראשי (root element) בלבד ולא יותר מכך.
אם המסמך כולל יותר ממרכיב ראשי אחד הדבר יגרום לכך שהוא כבר לא ייחשב ל-well-formed.
כמו כן, כל מסמך XML
חייב להיחשב ל-valid.
מסמך XML ייחשב ל-Valid אם
הוא well-formed וכמו כן, המבנה שלו
ותוכנו תואמים לכללים אשר נקבעו ב-DTD של אותו מסמך XML.
נושא ה-DTD יוסבר בהמשך.
תגית
ריקה
ניתן
לייצור תגית שתעמוד בזכות עצמה מבלי שיהיה צורך לסגור אותה בתגית סגירה. תגית כזו
תאופיין בלוכסן אשר יופיע לפני הסוגר שסוגר אותה. לדוגמא: <xxx/>
להלן
דוגמא לקטע מסמך XML אשר כולל בתוכו
תגית אשר עומדת בזכות עצמה:
<email to="sales@zindell.com" from="haim@zindell.com" topic="Java Is Really Cool"><important/>
<content> I love JAVA :) </content></email>
הערות
ב-XML
הערות במסמכי XML נראות בדיוק כמו הערות במסמכי HTML:
<!-- a comment ... -->
התחלתו
של מסמך ה-XML
בתחילת
כל מסמך XML יופיע משפט הקדמה
אשר יציין כי זהו מסמך XML וגם יכיל הצהרה
בנוגע לגרסת ה-XML שעל פיה המסמך
כתוב. להלן דוגמא למשפט הקדמה אפשרי:
<?xml version="1.0"?>
משפט ההקדמה מתחיל בסימן <? ומסתיים בסימן ?>. משפט ההקדמה יכול לכלול תכונות אשר מוסיפות אינפורמציה נוספת:
דוגמא:<?xml version="1.0" encoding="ISO-8859-1"?> להלן התכונות שניתן להוסיף אל תוך משפט ההקדמה:version
תכונה זו מציינת את גירסת ה-XML שנעשה בה שימוש. תכונה זו חייבת להופיע.
encoding
תכונה זו מציינת את ה-encoding (ה-character set) שמשמש במסמך.
standalone
מציינת אם מסמך ה-XML שנדון מכיל/איננו מכיל references למסמכים/מקורות נוספים.
ב-XML ולהבדיל מאשר ב-HTML הערכים אשר ניתנים לתכונות שמוסיפים חייבים להופיע בתוך גרשיים כפולים.
התחלתו של מסמך XML יכולה גם לכלול DTD או הפניה למסמך DTD חיצוני, אשר יכלול פירוט והבהרות של התגיות החוקיות לרבות אופן השימוש בהם וגם את הגדרתם של entities (כל זאת יוסבר בהמשך).
תחילתו של מסמך ה-XML יכולה גם לכלול processing instructions, הוראות לתכנית אשר תעבד את המסמך. המבנה הכללי של procession instructions הוא:
<? targetApplicationName theInstructions ?>
וזאת, כאשר ה-targetApplicationName הוא השם של האפליקציה אשר עתידה לעבד את המסמך ו-theInstructions הן ההוראות שניתנות. סדרת ההוראות שניתנת תיכתב כמחרוזת טקסט ארוכה אשר תכלול בתוכה את הפקודות ואת האינפורמציה הנוספת אשר מיועדים לאותה אפליקציה. מסמך XML יכול לכלול יותר מ-processing instructions אחד (לכל אפליקציה ייכתב processing instructions אחר).
מקטע
מסוג CDATA
אם
רוצים לשלב בתוך מסמך ה-XML טקסט שאיננו עומד
בכללי ה-well-formed (למשל, טקסט HTML
שמעונינים להציגו בדפדפן) ניתן לשלבו באמצעות מרכיב ה-CDATA
וכך, גם אם איננו well-formed עדיין מסמך ה-XML
כולו ייחשב ל-well-formed.
< ! [CDATA [ text text text . . . ] ] >
דוגמא:
<email to="sales@zindell.com" from="haim@zindell.com" topic="Java Is Really Cool"><important/>
<content><![CDATA [<hr> I love JAVA :) <br> and XML as well.<hr>] ]>
</content></email>
ה-DTD
כללים
נוספים שנרצה שתמיד יתקיימו במסמך XML שאנו כותבים נציין
ב-DTD. ה-DTD
יכול להיות מסמך חיצוני למסמך ה-XML או חלק ממסמך ה-XML או
גם וגם (בחלקו מהווה חלק ממסמך ה-XML ובחלקו מהווה מסמך
חיצוני). כך למשל, ניתן לכלול בתוך
ה-DTD כלל האומר שבתוך
המרכיב email יכול להיות רק
מרכיב content אחד. כאשר מסמך ה-XML
כולל גם DTD ניתן לבחון אותו
ולומר שהוא valid (או לא).
המידע
שכלול ב-DTD קרוי Meta
Data (זהו מידע על מידע).
בתחילת
המסמך ניתן להוסיף שורת הצהרה לגבי המסמך כולו, ואפילו להעניק לו שם. כך למשל,
משפט ההצהרה הבא מעניק למסמך כולו את השם MarketingEmail:
<!DOCTYPE MarketingEmail>
במשפט
ההצהרה ניתן גם לשלב הפניה לקובץ ה-DTD של אותו מסמךXML:
<!DOCTYPE MarketingEmail SYSTEM “MarketingEmail.dtd”>
הערך
שרושמים אחרי SYSTEM הוא
ה-URL של מסמך ה-DTD.
במקום
לרשום SYSTEM ומייד אחריה את שמו
של קובץ ה-dtd ניתן לרשום מספר
הגדרות DTD. דוגמא:
< ! DOCTYPE MarketingEmail
]
< ! ELEMENT content (#PCDATA) >] >
כך
למשל, הגדרות DTD אלה באות לציין כי בתוך המרכיב MarketingEmail
(הוא מרכיב השורש של המסמך) יכול להיות מרכיב בשם content
אשר יכול להכיל ערך טקסטואלי אך איננו יכול להכיל מרכיבים אחרים בתור ילדיו.
הגדרות
ה-DTD, כפי שכבר ציינו,
כוללות בעיקר מגבלות נוספות שאנו מעונינים להבטיח את התקיימותן במסמך ה-XML.
מקבץ הגדרות ה-DTD יכול לכלול את
ארבעת סוגי ההגדרות הבאים:
< ! ELEMENT . . . >
<
! ATTLIST . . . >
< ! ENTITY . . . >
< ! NOTATION . . . >
הגדרת מרכיבים (elements)
המבנה
הכללי של <! ELEMENT .
. . > הוא:
<!
ELEMENT name contentModel >
ה-name
הוא השם של המרכיב
שאליו מתייחסת ההגדרה.
ה-contentModel
מתאר את התוכן אשר
ייחשב לחוקי (valid)
באלמנט name.
האפשרויות
שיכולות להיות contentModel הן:
EMPTY האלמנט
יהיה ריק וללא תוכן. עדיין ניתן יהיה להוסיף אליו תכונות.
דוגמא:
< ! ELEMENT important EMPTY >
#PCDATA האלמנט
יכול להכיל תוכן טקסטואלי אך הוא לא יכול לכלול אלמנטים אחרים (child elements).
דוגמא:
< ! ELEMENT content (#PCDATA) >
תיאור
של אלמנטים אחרים האלמנט
יכול לכלול אלמנטים אחרים (child elements) והוא איננו יכול
לכלול תוכן טקסטואלי.
כדי
לקבוע מספר אלמנטים וכמו כן גם לקבוע את הסדר שבו הם יכולים להופיע יש לרשום את
שמות האלמנטים עם פסיקים ביניהם.
דוגמא:
< ! ELEMENT email (important, content) >
כדי
לקבוע שיש מספר אלמנטים אשר רק אחד מהם בא יוכל להיות יש לרשום את שמות האלמנטים
בצירוף הסימן | בין כל אחד ואחד. לחילופין, במקום הסימן | ניתן להשתמש ב-"or".
דוגמא:
< ! ELEMENT email (content | message) >
כדי
לקבוע שאלמנט מסוים יכול להופיע אפס, פעם אחת או מספר אינסופי של פעמים יש לסמנו
ב- *. כדי לקבוע שאלמנט מסוים יכול להופיע פעם אחת או יותר (אך האלמנט חייב להופיע
לפחות פעם אחת) יש לסמנו ב- +. כדי לקבוע שאלמנט מסוים יכול להופיע פעם אחת או כלל
לא להופיע יש לסמנו ב- ? . באמצעות סוגריים ניתן לקבץ מספר אלמנטים יחדיו לקבוצה
של אלמנטים ובדרך זו להשתמש בסימנים *, + או ? על אותה קבוצה מסוימת.
דוגמא:
< ! ELEMENT email (important?, content) >
שילוב
של אלמנטים אחרים או #PCDATA האלמנט יכול לכלול אלמנטים אחרים (child elements) או תוכן טקסטואלי.
ניתן
ליצור DTD אשר יגדיר כי אלמנט
מסוים יכול לכלול אלמנטים אחרים או תוכן טקסטואלי.
דוגמא:
< ! ELEMENT content (#PCDATA | message) >
ANY האלמנט
יכול להכיל כל דבר.
דוגמא:
< ! ELEMENT content ANY >
רק
כאשר ה-contentModel הוא ANY או
EMPTY אז לא יופיעו
סוגריים (סביב EMPTY או סביב ANY).
הגדרת תכונות (attributes)
המבנה
הכללי של <! ATTLIST .
. . > הוא:
<!
ATTLIST elementName attributeName attributeType default
attributeName attributeType default
. . .
>
ה-
attributeName הוא השם
של ה-attribute, ה-attributeType הוא הטיפוס של ה-attribute וה-default הוא ערך ברירת המחדל שנותנים לאותו attribute.
דוגמא:
<! ATTLIST email to CDATA #REQUIRED
from CDATA #REQUIRED
topic CDATA #IMPLIED >
האפשרויות
שקיימות כאשר קובעים ערך ברירת מחדל הן:
#REQUIRED
תכונה
זו חייבת לקבל ערך.
#IMPLIED
תכונה
זו לא חייבת לקבל ערך. אם היא לא מקבלת ערך אין כל ערך ברירת מחדל אשר יינתן לה.
ערך
ניתן
לקבוע ערך ברור אשר ישמש בתור ערך ברירת המחדל.
#FIXED
בכתיבת
#FIXED
כשמייד אחריו ערך מסוים אם התכונה תקבל ערך אז הוא חייב יהיה להיות שווה לאותו ערך
מסוים שנכתב אחרי #FIXED.
האפשרויות
שקיימות כאשר קובעים טיפוס לתכונה הן:
CDATA
כל
טקסט בהתאם למגבלות כפי שנקבעו ב-XMLspecifications
(כך למשל, טקסט זה לא יוכל לכלול סמנים כגון > ו- <).
NMTOKEN
כמו
CDATA למעט המגבלה הבאה:
התווים שיכולים להיכלל הם רק התווים ש-XML specifications
מאפשרים שיופיעו בשם שנותנים לXML elements . כך למשל, ריווחים לבנים
לא יוכלו להופיע.
NMTOKENS
הערך
יוכל להיות מספר NMTOKEN עם ריווחים לבנים
אשר יפרידו ביניהם.
Enumerations
הערך
יוכל להיות אחד הערכים אשר נקבעו כקבוצת הערכים האפשריים.
דוגמא:
<! ATTLIST email to CDATA #REQUIRED
from (info,marketing,accounting,ceo) #REQUIRED
topic CDATA #IMPLIED >
ID
כאשר
זהו הטיפוס של תכונה מסוימת אז אותה תכונה יהיה לה ערך ייחודי בכל אחד ממופעיה
(בהקשר של האלמנטים השונים). ערכה של תכונה מטיפוס זה חייב להתחיל באות, קו תחתי
או נקודותיים. כמו כן, ערך ברירת המחדל של תכונה שטיפוסה נקבע להיות ID
חייב להיות #IMPLIED או
#REQUIRED.
דוגמא:
< ! DOCTYPE Project
[
<! ELEMENT Project (Leader|eveloper|Programmer) * >
<!
ATTLIST Leader employeeId ID #IMPLIED >
<!
ATTLIST Developer employeeId ID #IMPLIED >
<!
ATTLIST Programmer employeeId ID #IMPLIED >
] >
<Project>
<Leader employeeId=”123123”> <Developer employeeId=”3233232”> <Developer employeeId=”4343432”> <Programmer employeeId=”5432343”> <Programmer employeeId=”44433322”>
</Project>
IDREF
כאשר
זהו הטיפוס של תכונה מסוימת אז אותה תכונה יהיה לה ערך ייחודי אשר יהיה שווה לערך
התכונה ID באלמנט אחר.
באמצעות תכונה מטיפוס IDREF ניתן ליצור מבנה של
אלמנטים שמחוברים אחד לשני בדומה לרשימה מקושרת.
הגדרת יישויות (entities)
המבנה
הכללי של <! ENTITY . .
. > הוא:
<
! ENTITY name “entityContent”>
דוגמא:
<
! ENTITY copyright “All the rights reserved to Haim Michael & Zindell Ltd.
© copyright”>
לאחר
יצירת ה-entitiy (בדוגמא זו: copyright הוא שמה), בכל מקום שבו ייכתב copyright&
זה יוחלף בערכה של אותה entity: “All
the rights reserved ...”.
בהגדרתה
של entity ניתן לקבוע כי תהיה
שווה לתוכנו של מסמך XML אחר. כדי לעשות
זאת, ה-entityContent יהיה שווה למילה SYSTEM
כשאחריה שמו (כתובת ה-URL) של מסמך ה-XML
האחר אשר תוכנו יהיה ערכה של ה-entity המוגדרת.
דוגמא:
< ! ENTITY copyright SYSTEM “ZindellCopyright.xml”>
בדרך
זו, תוכנו של המסמך ZindellCopyright.xml
יוכנס בכל מקום שבו יופיע ©right. ניתן לראות דמיון
רב בין אופן פעולתה של entity לבין הפקודות #include ו-#define משפות התכנות שהיו
לפני ש-JAVA הופיעה: C\C++.
ניתן
להגדיר ישויות עבור מסמך/מקטע ה-DTD. כדי לעשות זאת יש
להשתמש בסימן % במקום בסימן &.
דוגמא:
< ! ENTITY % attImp “CDATA #IMPLIED”>
.
, ,
< ! ATTLIST Product name %attImp;
id CDATA #REQUIRED>
הגדרת Notations
המבנה
הכללי של <! NOTATION .
. . > הוא:
<
! NOTATION notationName SYSTEM executeableFileName>
דוגמא:
<
! NOTATION game SYSTEM “nintandu.exe”>
באמצעות
הגדרת Notation ניתן לקשר בין
יישויות חיצוניות (קבצי XML אחרים) לתכנית מחשב
אשר תפעל עליהם בכל מקום שבו הם ישולבו. כך למשל, בהגדרת ה-ENTITY
הבא:
<! ENTITY pacman SYSTEM pac.xml NDATA game>
בכל
מקום שבו תשולב הישות pacman תשולב התוצאה שתופק
באמצעות הפעלת ה-application: nintandu.exe על
המסמך pac.xml.
כדי
להבטיח שבמתן שמות שונים למרכיביו השונים של מסמך ה-XML לא
ייוצר מצב שבו שמות של אלמנטים שונים יחזרו על עצמם יש לקבוע את שמו של מרכיב (element) באופן שבו הוא יהיה
מורכב משני שמות עם נקודותיים ביניהם. השם הראשון כמוהו כשם משפחה והשם השני כמוהו
כשם פרטי. בדרך זו קטן הסיכויי לקבלת כפילות בשמות האלמנטים אשר נקבעים.
דוגמא:
<Zindell:Project>
<Product:Id>123321</Product:Id>
<ProjectManager:Id>2454567</ProjectManager:Id>
</Zindell:Project>
הקדמה
יתרונות
רבים קיימים בשימוש שניתן לעשות ב-XML. חלק זה יסקור
יתרונות אלו.
היתרונות
מתן תוויות זיהוי לנתונים
תגיות ה-XML אינן מציינות כיצד יש להציג בדפדפן את אותם נתונים שהן מסמנות (כמו תגיות HTML). תגיות ה-XML רק מקנות משמעות לאותם נתונים שהן מסמנות. תגיות ה-XML כלל וכלל אינן מציינות כיצד להציג את אותם נתונים. מסיבה זו, תכנית אשר מעבדת מסמך XML יכולה, בקלות יחסית, לחלץ ממנו את פרטי המידע שיש בו (בקלות רבה יותר מאשר אילו זה היה מסמך HTML). במסמכי HTML כל שינוי בהוראות כיצד להציגו (כלומר, שינוי בתגיות שלו) דורש שינוי מתאים באפליקציות אשר מפענחות את אותו מסמך, ומחלצות ממנו את פרטי המידע. במסמכי XML, כל שינוי באופן הצגתו של המסמך הנו שינוי ב-XSL או ב-CSS ולא שינוי במסמך עצמו.
מסמך XML הוא מסמך טקסט פשוט
כיוון שמסמך XML הוא מסמך טקסט פשוט אין כל קושי לערוך אותו ולהבין מהם הנתונים שהוא מכיל. מסיבה זו, השימוש במסמכי XML לקביעת configuration settings לאפליקציות (שרתים למשל) נוח ביותר. כמו כן, כיוון שמסמכי XML הם מסמכי טקסט פשוטים קל לדבג (debugging) אותם. שימוש יעיל נוסף שניתן לעשות במסמכי XML הוא אחסונם של נתונים לאורך זמן. מסמך XML אשר מחזיק בתוכו נתונים הוא אמצעי אחסון מצוין בהשוואה לאלטרנטיבות:
- שמירת נתונים בדרך של ביצוע serialization לאובייקט/ים שברירית למדי. כל פגיעה קטנה בקובץ תפגע קשות בחילוץ הנתונים שבתוכו. כמו כן, אם בעוד שנים רבות, ארכיאולוג שייתקל בקובץ שנשמרו בו אובייקטים בדרך של serialization ינסה לחלץ את הנתונים שבו כלל לא בטוח שהוא יצליח בכך (אולי Java תעבור שינויים כאלה שזו תהיה משימה כמעט בלתי אפשרית).
- העברת נתונים בין אפליקציות באמצעות מסמך XML יכולה להיעשות בין תכניות שפיתוחן נעשה בשפות ובפלטפורמות שונות. מסמך XML נייטראלי בכל הקשור לפלטפורמות ולסביבות שמשתמשות בו. זו אחת הסיבות המרכזיות לשימוש הנרחב שיש ל-XML בתחום ה-B2B.
האפשרות לבצע inline
כאשר יוצרים מסמך XML ניתן לשלב בתוכו entities (מסמכי XML אחרים אשר משולבים במסמכים ובמקומות שונים). האפשרות ליצור entity ולשלבו שוב ושוב במסמכים ובמקומות שונים בעוד שמקבל המסמך (אשר כולל בתוכו שילוב של entities) מקבל אותו כיחידה אחת מבלי להבחין בשימוש שנעשה ב-entities מקל על פיתוחם ותחזוקתם של מסמכי ה-XML. השימוש ב-inline elements דומה לאפשרות שקיימת בשפת C לבצע include.
מסמך XML איננו כולל הוראות בנוגע לאופן שבו יש להציג אותו. ההוראות בנוגע לאופן שבו יש להציגו נכללות בקובץ נפרד, קובץ ה-XSL. הודות להפרדה זו, ניתן בקלות רבה להציג את הנתונים שבמסמך ה-XML בדרכים ובפורמטים שונים לרבות כאלה שטרם נקבעו ושיומצאו בעתיד. כפי שכבר צוין, הפרדה זו מקלה רבות על אפליקציות אשר מחלצות את הנתונים שמופיעים במסמך XML.
השימוש ב-XSL
מסמך XML לא כולל הוראות בנוגע לאופן שבו יש להציג אותו. ההוראות בנוגע לאופן שבו יש להציגו נכללות בקובץ נפרד, קובץ ה-XSL. הודות להפרדה זו, ניתן בקלות רבה להציג את הנתונים שבמסמך ה-XML בדרכים ובפורמטים שונים גם כאלה שיומצאו בעתיד. כפי שכבר צוין, הפרדה זו מקלה רבות על אפליקציות אשר מחלצות את הנתונים שמופיעים במסמך XML.
אפשרויות לשלב קישורים בתוך המסמך
פרט לאפשרות לשלב קישורים פשוטים למסמכים אחרים, XML מאפשרת גם לשלב קישורים שהפעלתם תגרום לשילובם של מסמכים אחרים בדיוק באותו מקום שבו הם הופיעו. XML מאפשרת את שילובם של קישורים מסוגים אחרים אשר מאפשרים לבצע פעולות שונות ומגוונות (יוסבר בהמשך).
מסמך XML חייב להיות ל-well formed
בניגוד למסמך HTML, מסמך XML חייב להיות well formed טרם שיעבור parsing (חילוץ הנתונים שבתוכו). זוהי עוד סיבה לכך שיותר קל לכתוב תכניות אשר מחלצות את הנתונים שמופיעים בתוך מסמך XML מאשר תכניות אשר מחלצות את הנתונים אשר מופיעים בתוך מסמך HTML.
מבנה הירארכי של הנתונים
כיוון שהנתונים שמוחזקים בתוך מסמך ה-XML מוחזקים במבנה הירארכי קל יותר לחלץ נתון מתוך המסמך – בין אם זאת נעשה על ידי תכנית אשר מבצעת parsing ובין אם זאת נעשה על ידי אדם המתבונן במסמך.
הקדמה
שפת התכנות Java ושפת הסימון XML משתלבים יחד באופן מצוין. שתי השפות ניטראליות מכל פלטפורמה ספציפית (הן יכולות לפעול על כל פלטפורמה) ושתיהן יכולות לעבוד במשולב באופן יעיל ביותר, לא מעט הודות לפיתוחן של מחלקות חדשות אשר תומכות בשיתוף הפעולה שנעשה ביניהן.
דחיפה רצינית למידת השימוש ב-XML תינתן עם קביעתם של סטנדרטים ביצירת מסמכי XML בתחומי התעשייה השונים. כך, למשל, כאשר יקבעו התגיות שישמשו לתיאור נתונים פיננסיים בנקאיים, העברת הנתונים בין בנקים ומוסדות פיננסיים שונים באמצעות מסמכי XML תהיה הרבה יותר קלה לביצוע.
בחלק זה ייסקרו האפשרויות העיקריות שקיימות בשילוב שבין XML ו-Java.
תכניות
ב-Java אשר מפענחות מידע
ששמור במסמכי XML ומייצרות מסמכי XML כדי לתאר נתונים אחרים
תכניות שרת-לקוח יכולות לשלוח ולקבל מסמכי XML אחת לשניה ובכך לשלוח אינפורמציה בשני הכיוונים. בעתיד, כאשר ייקבעו קבוצות של תגיות כסטנדרט ליצירת מסמכי XML בתחומים השונים, אפשרויות השימוש ב-XML לשליחת/קבלת נתונים יתרחבו.
קבצי
archive אשר מתארים הגדרות
של מחלקות/אובייקטים
ניתן באמצעות מסמכי XML לתאר הגדרה של מחלקה ולעשות בה שימוש חוזר. מסמך ה-XML יישמר וייקרא מחדש מאוחר יותר ועל פי ההגדרות שמופיעות בתוכו המחלקה המתוארת תשוחזר ואולי אף ייווצר ממנה אובייקט. בדרך זו, יתאפשר גם להעביר קובץ אשר מגדיר מחלקה מסוימת לתכנית בשפה אחרת ולאפשר לתכנית האחרת ליצור מחלקה על פי הנתונים שבאותו קובץ. שמירת תיאור המחלקה בקובץ XML יקל גם ביצועם של שינויים באופן ההגדרה של המחלקה (החלפת תגית XXX בתגית YYY למשל היא מהלך פשוט למדי שלא אורך זמן רב). ניתן בצורה פשוטה לשנות את הגדרותיהן של מחלקות רבות (למשל, להחליף את התגית XXX בתגית YYY בכל קבצי ה-XML שמתארים את המחלקות שאת הגדרתן רוצים לשנות).
באופן דומה, ניתן להשתמש ב-XML כדי לתאר אובייקטים. תיאור של אובייקט באמצעות מסמך XML עדיף על פני תיאורו באמצעות קובץ בינארי שמכיל את תיאור האובייקט אשר עבר serialization. מסמך XML קל יותר לשינוי מאשר קובץ בינארי. קובץ XML קל להעברה בין תכניות בשפות שונות כך שאותו אובייקט שמתואר במסמך ה-XML יוכל לעבור תהליך של שיחזור לאובייקט בשפה אחרת.
מסמכי
XML אשר כוללים בתוכם references לרכיבי ה-GUI שצריכים להיות ול-EJB אשר יפעלו Document-Driven
Programming (DDP)
אחד הכיוונים שבהם XML מתפתחת הוא להכללתם (בתוך מסמך ה-XML) של references למרכיבי GUI אשר יוצגו במסמך ול-EJB אשר יפעלו ברקע. בדרך זו, בזמן הצגתו של מסמך XML (בזמן ריצה) יקבעו ה-GUI components אשר יוצגו על המסך וכמו כן ייקבעו ה-EJB אשר יפעלו ברקע. כיוון זה נמצא כעת בשלבי התפתחות ראשונים (ייתכן שכאשר את/ה קורא/ת שורות אלה כיוון זה כבר מצוי בשלביו המתקדמים).
יצירה
אוטומאטית של המחלקות המתאימות לעיבוד הנתונים אשר מופיעים במסמך
על בסיס ה-DTD ניתן לכתוב תכנית אשר תדע לייצור באופן אוטומאטי את המחלקות המתאימות לעיבוד המרכיבים אשר מופיעים במסמך ה-XML.
JAXP API (Java Api for Xml Parsing)
המחלקות של ה- JAXP API שמורות בקובץ jaxp.jar. מחלקות אלה מקובצות ל-package אחד: javax.xml.parsers. ב-package זה כלולות, בין היתר, שתי המחלקות הבאות: SAXParserFactory ו- DocumentBuilderFactory. הראשונה מאפשרת לבצע parsing למסמך XML נתון והשניה מאפשרת ליצור DOM מתאים למסמך XML נתון.
תחילה,
כדי שניתן יהיה להמשיך, יש להתקין את JAXP,
ה-Java API for XML Processing. זהו Standard
Extension אשר מאפשר קריאה (parsing), שינוי והפקה של
מסמכי XML. תוספת זו מאפשרת
קבלת אחידות בשימוש שנעשה ב-parser חיצוני. ה-JAXP
משתמש (כברירת מחדל) ב- Java Project X בתור ה-default
parser. עם זאת, ניתן לשלב במחלקות המסופקות על ידי JAXP
שימוש ב-parsers אחרים. הגרסה שעל
פיה פרק זה נכתב היא JAXP 1.1ea2. גרסה זו כוללת
תמיכה מלאה בתקנים הבאים:
XML 1.0 Specifications
SAX2.0
DOM Level 2 Core
XML namespaces
XSL
תוספת
זו ניתנת להורדה מן האתר הרשמי של Java, http://www.javasoft.com.
יש
לוודא שהקבצים crimson.jar ו-jaxp.jar
יוספו ל-classpath של המחשב או, לחילופין,
לדאוג שיישמרו בתיקיה ext תחת lib
אשר תחת jre אשר תחת jdk1.3.
אם את/ה משתמש/ת ב-jdk1.4 אז ה-JAXP
כבר מותקן אצלך כחלק מה-core.
שימוש
בJAXP- לביצוע parsing פשוט
בשלב
זה תוצג האפשרות לבצע parsing באמצעות SAX.
ראשי התיבות של SAX הן: Simple
API for XML. ה-JAXP כולל בתוכו את SAX.
תחילה,
כדי שניתן יהיה להמשיך, יש להתקין את JAXP,
ה-Java API for XML Processing. זהו Standard
Extension אשר מאפשר קריאה (parsing), שינוי והפקה של
מסמכי XML.
הרעיון
שבבסיס הפעלת המחלקות המתאימות מתוך SAX
לשם ביצוע parsing הוא קביעתו של
אובייקט מסוים בתור האובייקט שעליו יופעלו מתודות מסוימות תוך כדי ביצוע ה-parsing.
אובייקט זה חייב להיווצר ממחלקה שמיישמת את ה-interfaces
הבאים:
EntityResolver
DTDHandler
ContentHandler
ErrorHandler
ניתן
להשתמש במחלקה DefaultHandler אשר מיישמת כבר interfaces
אלה או, לחילופין, להגדיר מחלקה חדשה למטרה זו.
תהליך
ה-parsing באמצעות SAX
נעשה באמצעות events אשר נוצרים במהלך
ה-parsing בהתאם לתוכנו של
המסמך. עם התרחשותו של כל אחד מן ה-events מופעלת המתודה
המתאימה. כך למשל, אם מסמך ה-XML שמבצעים לו parsing
הוא המסמך הבא:
<? xml version=”1.0” ?>
<xmlDocument>
<title>I
LOVE XML & JAVA</title>
This
is it !
</xmlDocument>
ניתן
לומר כי המתודות אשר תופעלנה על ה-listener (בהתאם ל-events
אשר מתרחשים) הן:
startDocument()
startElement() : xmlDocumentstartElement() : titlecharacters() : I LOVE XML & JAVAendElement() : titlecharacters() : This is it !endElement() : xmlDocumentendDocument()
התרשים
הבא מציג את הקשרים אשר קיימים בין המחלקות וה-interfaces
השונים ב-package: SAX
2.0.
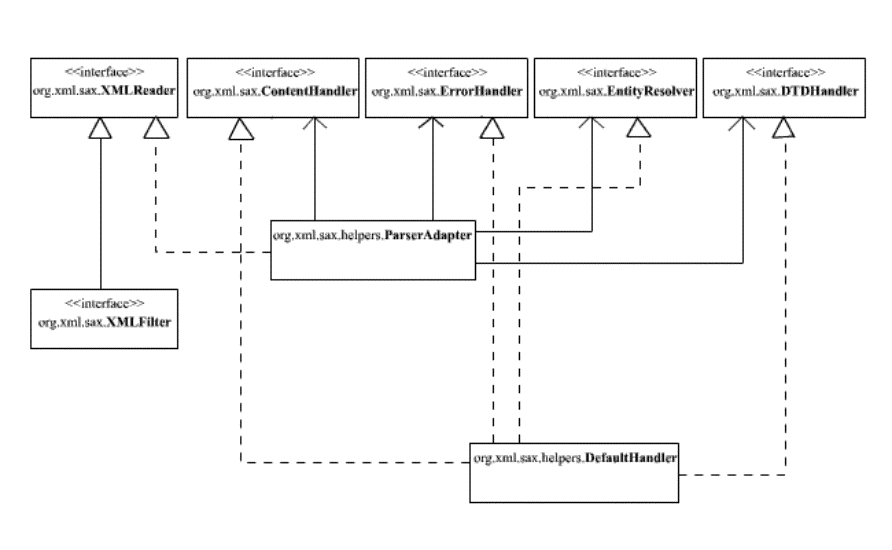
ה-interface: XMLReader
כולל את המתודות העיקריות בתהליך ה-parsing.
ה-interface: ContentHandler
כולל את המתודות שמופעלות בהתאם ל-events שמתרחשים (בדומה ל-KeyListener או
אחד ה-interfaces האחרים ה-delegation
model).
ה-interface: ErrorHandler
כולל את המתודות שיופעלו כאשר יתרחשו errors.
ה-interface: EntityResollver
כולל את המתודות שיופעלו כדי לטפל ב-entities.
ה-interface: DTDHandler
כולל את המתודות
שיופעלו כדי לטפל ב-events שקשורים ב-DTD של
המסמך.
המחלקה:
DefaultHandler מיישמת את ארבעת ה-interfaces: ContentHandler, ErrorHandler, EntityResolver ו-DTDHandler.
זוהי מחלקה קונקרטית שכל אחת מן המתודות שהגיעו אליה מה-interfaces
שמיושמים בה הוגדרו ללא גוף (בדומה למחלקות ה-adapter
אשר הוגדרו ב-delegation model).
בין
יתר המתודות אשר הוגדרו במחלקה XMLReader יש מתודות אשר
מאפשרות לקבוע ב-parser: features ו-methods
ובכך לקבוע את אופן פעולתו.
חברות
וגופים שונים פיתחו API שונים שיכולים לשמש
כ-SAX Parsers. אחד המימושים של SAX
Parser הוא המימוש של SUN, אשר כלול ב-JAXP.
כדי
לקבל לידינו reference לאובייקט אשר יוכל לבצע parsing
יש, תחילה, להפעיל
את המתודה הסטטית newInstance אשר הוגדרה במחלקה SAXParserFactory.
מתודה זו מחזירה reference לאובייקט מטיפוס SAXParserFactory.
על אובייקט זה ניתן יהיה להפעיל את המתודה newSAXParser
אשר תחזיר reference לאובייקט מטיפוס SAXParser(זהו
האובייקט אשר יוכל לבצע parsing), אובייקט שבהמשך
ניתן יהיה להפעיל עליו את המתודה parse. המתודה parse
מקבלת שני ארגומנטים: הארגומנט הראשון מייצג את הקובץ שרוצים לעשות לו parsing
והארגומנט השני מייצג את האובייקט אשר מיישם את ארבעת ה-interfaces
שהוזכרו (אובייקט מטיפוס מחלקה שיורשת מ-DefaultHandler
למשל). אובייקט זה יפעל כ-listener אשר יגיב לאירועים
שמתרחשים תוך ביצועו של תהליך ה-parsing. את שהוסבר ניתן
לסכם בשלבים הבאים:
SAXParserFactory
factory = SAXParserFactory.newInstance();
SAXParser
saxParser = factory.newSAXParser();
saxParser.parse(... , ... );
הארגומנט הראשון יכול, למשל, להיות reference לאובייקט שהוא stream למסמך ה-XML שרוצים לעשות לו parsing. המתודה parse מוגדרת במספר גרסאות (overloading methods).
כדאי לשים לב למתודות אשר מוגדרות במחלקה SAXParserFactory אשר מאפשרות לקבוע אפיונים שונים של אובייקט ה-SAXParser אשר מתקבל באמצעות הפעלת המתודה newSAXParser.
בדוגמא הבאה מודגמת הגדרתה של מחלקה אשר יורשת מ-DefaultHandler באופן שבו אובייקט מטיפוסה ישמש כמי שמבצע parsing, או ליתר דיוק, כמי שישמש כ-event listener ל-events השונים אשר מתרחשים במהלך ה-parsing.
להלן מסמך ה-XML שעליו ה-parsing יתבצע:
<?xml version="1.0"?>
<course>
<trainer>
<firstName>Haim</firstName>
<lastName>Michael</lastName>
</trainer>
<topic>
Java Programming ...
</topic>
</course>
להלן תכנית הדוגמא בצירוף ההגדרה של המחלקה אשר יורשת מ-DefaultHandler:
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
import java.io.*;
class MySAXParserHandler extends DefaultHandler
{
public void startDocument() throws SAXException
{
System.out.println("document start");
}
public void endDocument() throws SAXException
{
System.out.println("document end");
}
public void characters(char[] vec, int start, int length)
throws SAXException
{
String str = new String(vec,start,length);
System.out.println("characters : "+str);
}
public void startElement(String uri, String name, String qName, Attributes atts)
throws SAXException
{
System.out.println("start element : " + qName);
for(int i=0; i<atts.getLength(); i++)
{
System.out.print("attribute name : " + atts.getLocalName(i));
System.out.println(" value : " + atts.getValue(i));
}
}
public void endElement(String uri, String name, String qName)
throws SAXException
{
System.out.println("end element : " + qName);
}
public void ignorableWhitespace (char[] vec, int start, int length)
throws SAXException
{
System.out.println("number of spaces that were ignored is " + length);
}
public void startPrefixMapping(String str) throws SAXException
{
System.out.println("start of prefix : " + str);
}
public void endPrefixMapping(String str) throws SAXException
{
System.out.println("end of prefix : " + str);
}
public void processingInstruction(String str, String data) throws SAXException
{
System.out.println("instruction : " + str + " data : " + data);
}
public void skippedEntity(String str) throws SAXException
{
System.out.println("skip on entity : " + str);
}
public void error(SAXParseException exception)
throws SAXException
{
System.out.println("error happened : " + exception.getMessage());
}
public void fatalError(SAXParseException exception)
throws SAXException
{
System.out.println("fatal error happened : " + exception.getMessage());
}
public void warning(SAXParseException exception)
throws SAXException
{
System.out.println("warning : " + exception.getMessage());
}
}
public class ParsingDemo
{
public static void main(String args[])
{
try
{
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
parser.parse(new InputSource(new FileReader("xmlSample.xml")), new MySAXParserHandler());
}
catch(Exception e)
{
e.printStackTrace();
}
}
}
2000 © All the rights reserved to
Haim Michael & Zindell Publishing House Ltd.
No parts of the
contents of this paper may be reproduced or transmitted
in any form by any means
without the written permission of the publisher !
This book can be used
for personal use only!!!
Brought to you by
ZINDELL
לנוחיותך, להלן
תוכן העניינים של הספר:
פרק 1: ההתחלה Let's start -
פרק 2: הבסיס Basic -
פרק 3: מחלקות Classes -
פרק 4: מערכים ומחרוזות תוויםArrays & Strings -
פרק 5: הורשהInheritance -
פרק 6: ניתוח
מרכיביה של מחלקהReflection
-
פרק 7:
מחלקות פנימיותInner Classes -
פרק 8: יישומוניםApplets -
פרק 9: תכנות מקביליThreads -
פרק 10: ממשק משתמש גרפי בסיסי Graphic User Interface using AWT -
פרק 11: הטיפול באירועים Events Handling -
פרק 12: הטיפול בשגיאות Exceptions Handling -
פרק 13: פעולות קלט/פלט I\O Streams -
פרק 14: תקשורתNetworking -
פרק 15: ממשק משתמש גרפי
מתקדם Graphic User
Interface using SWING -
פרק 16: מבני
נתונים Data
Structures -
פרק 17: מחלקות מוכנות לתיאור
מבני נתונים Collections
API -
פרק 18:
קישור לבסיס נתונים - JDBC
פרק 19:
הפעלת מתודות מרחוק RMI -
פרק 20:
הסבת התכנית למדינות אחרותInternationalization -
פרק 21:
שילוב קוד בC- Native Methods (JNI) -
פרק 22:
שימוש בXML-
פרק 23:
אבטחת מידע Security -
פרק 24:
גרפיקה דו ממדית 2D Graphics -
פרק 25: ניהול הזיכרון Memory Management -
נספחים:
נספח א': אופן הפעלת ה-javadoc
נספח ב': הכרות ראשונית עם UML
נספח ג': הכרות ראשונית עם Design Patterns
נספח ד': שיפור הביצועים של התכנית
נספח ה': כללי תחביר בכתיבת קוד מקור
נספח
ו': פקודות
שכיחות ב-SQL